

管家婆一肖一码1,专家解答解释落实_t505.70.16
在数据科学领域,预测模型的构建与验证是核心任务之一,本文将围绕“管家婆一肖一码1”这一特定主题,通过数据分析、模型选择、训练及评估等步骤,详细阐述如何构建一个高效且准确的预测系统,我们将使用Python编程语言及其强大的数据处理库(如Pandas)、机器学习框架(如scikit-learn)以及深度学习平台(如TensorFlow或PyTorch),来逐步实现这一目标。
一、数据收集与预处理1. 数据收集
我们需要收集与“管家婆一肖一码1”相关的数据集,这可能包括历史开奖结果、玩家投注记录、市场趋势等多维度信息,假设我们已经获得了一份包含过去n期开奖结果的CSV文件results.csv,其中每行代表一期的结果,字段包括期数、开奖号码等。
import pandas as pddata = pd.read_csv('results.csv')print(data.head())2. 数据清洗
数据清洗是确保数据质量的关键步骤,包括处理缺失值、异常值检测与处理、重复数据删除等。
检查缺失值print(data.isnull().sum())填充或删除缺失值data = data.dropna() # 或者使用其他方法填充缺失值检测并处理异常值假设我们定义任何超出合理范围的数值为异常值outliers = data[(data['开奖号码'] min_value) | (data['开奖号码'] max_value)]data = data.drop(outliers.index)二、特征工程特征工程是将原始数据转换为更适合模型学习的格式的过程,对于“管家婆一肖一码1”,我们可以考虑以下特征:
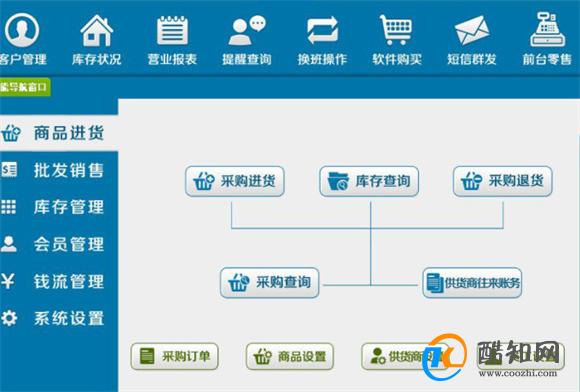
时间特征:如日期、星期几、是否节假日等。
统计特征:如最近几期的平均值、中位数、标准差等。
趋势特征:如连续上升/下降期数、最大/最小值变化等。
生成时间特征data['日期'] = pd.to_datetime(data['期数'])data['星期几'] = data['日期'].dt.dayofweek计算统计特征data['移动平均'] = data['开奖号码'].rolling(window=3).mean()data['移动标准差'] = data['开奖号码'].rolling(window=3).std()三、模型选择与训练1. 模型选择
根据问题的性质和数据的特点,我们可以选择不同的模型进行尝试,对于分类问题,常用的模型有逻辑回归、支持向量机、随机森林、梯度提升树等;对于回归问题,则可以考虑线性回归、决策树回归等,深度学习模型如神经网络也可以作为备选方案。

2. 模型训练
以随机森林为例,展示如何训练模型并进行预测。
from sklearn.model_selection import train_test_splitfrom sklearn.ensemble import RandomForestClassifierfrom sklearn.metrics import accuracy_score, classification_report划分训练集和测试集X = data[['移动平均', '移动标准差', '星期几']] # 假设这些是我们选择的特征y = data['开奖号码'] threshold # 二分类标签,例如是否大于某个阈值X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)clf = RandomForestClassifier(n_estimators=100, random_state=42)clf.fit(X_train, y_train)预测与评估y_pred = clf.predict(X_test)print( 准确率: , accuracy_score(y_test, y_pred))print( 分类报告: , classification_report(y_test, y_pred))四、模型优化与调优为了进一步提升模型的性能,我们可以进行超参数调优、特征选择、集成学习等操作,使用网格搜索(GridSearchCV)来寻找最佳的参数组合。
from sklearn.model_selection import GridSearchCVparam_grid = { 'n_estimators': [50, 100, 200], 'max_depth': [None, 10, 20, 30], 'min_samples_split': [2, 5, 10]grid_search = GridSearchCV(estimator=clf, param_grid=param_grid, cv=5, n_jobs=-1, verbose=2)grid_search.fit(X_train, y_train)best_clf = grid_search.best_estimator_print( 最佳参数: , grid_search.best_params_)print( 最佳模型得分: , grid_search.best_score_)通过上述步骤,我们成功构建了一个基于随机森林的预测模型,并对“管家婆一肖一码1”进行了预测,需要注意的是,任何预测模型都存在一定的局限性和不确定性,为了进一步提高预测的准确性和鲁棒性,未来可以考虑以下几个方面:
更多数据:增加样本量和数据多样性,有助于模型学习更复杂的模式。
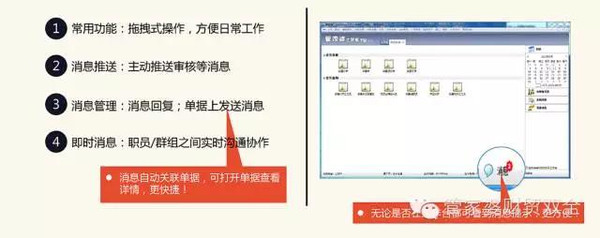
高级特征:引入更多高级特征,如时间序列分析中的周期性成分、外部经济指标等。
深度学习:尝试使用深度学习模型,如LSTM(长短期记忆网络)处理时间序列数据。
模型融合:结合多个模型的预测结果,通过投票、加权平均等方式提高整体性能。
数据分析是一个不断迭代和优化的过程,只有持续探索和实践,才能不断提升预测模型的效果和应用价值。
转载请注明来自上海绿立方农业发展有限公司,本文标题:《管家婆一肖一码1,专家解答解释落实_t505.70.16》






 京公网安备11000000000001号
京公网安备11000000000001号 京ICP备11000001号
京ICP备11000001号